4. 学習の例
4.1 実世界に近い環境での柔軟な認識の学習

図4-1-1 首振りタスク学習時の実験環境。白AIBOは固定。黒AIBOは首を動かし、白AIBOを正面に捉えた時に吠えると報酬、それ以外の時に吠えると罰が与えられる。
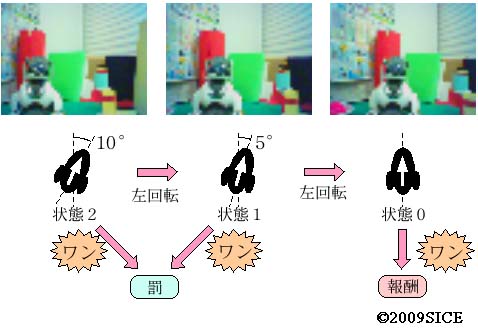
図4-1-2 首振りタスクの状態遷移の例。実際は,毎ステップ背景等が変化する。
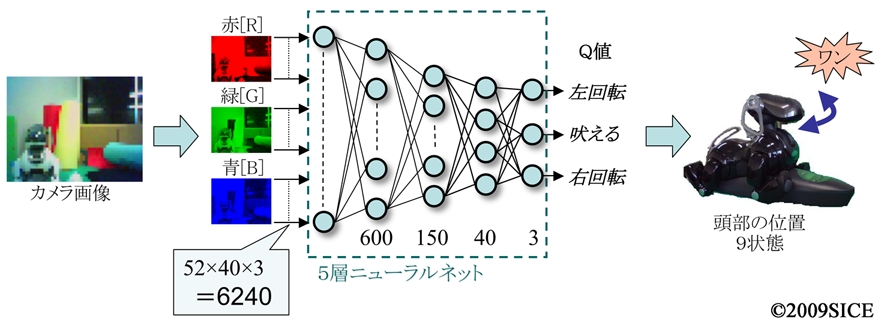
図4-1-3 首振りタスクの入出力。カメラ画像がそのままニューラルネットへ入力されて,Q-learningで正しく吠えた時の報酬と間違えて吠えたときの罰から学習される。その他の,画像処理,画像認識,タスクに関する情報は一切与えない。

図4-1-4 首振りタスクの入力画像のサンプル。本文中の図2は歩行タスクのサンプル画像

動画4-1-1 首振りタスクの学習後のテストの動画(ダウンロード,WMVファイル(1.25MB),MPGファイル(5.37MB))

図4-1-5 最下層の中間層ニューロンの最初の116個分の,入力からの結合の重み値の学習による変化を画像化したもの。

図4-1-6 真ん中の中簡層の150個すべてのニューロンの表現を画像化したもの。本文中の図3(b)はその一部。
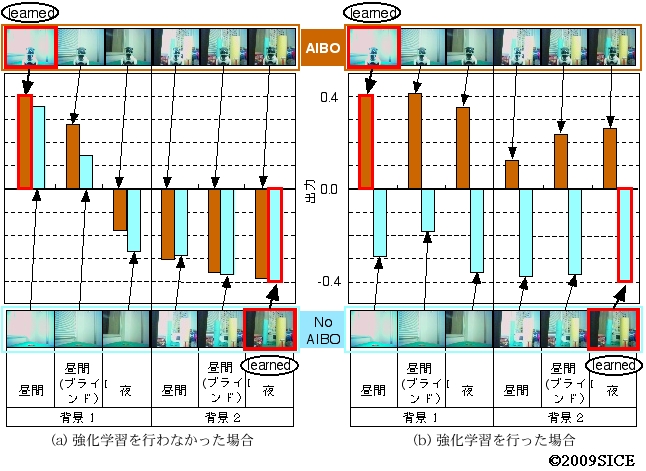
図4-1-7 出力層のニューロンを新たに1個追加し,そのニューロに対し,図中の赤枠で囲んだ2つの画像を見せて,AIBOがいて明るくて背景に物体をおいていない場合に0.4の教師信号を,AIBOがおらず,暗くて背景に物体が置いてある画像に対し-0.4の教師信号を与えて学習させた。そして,学習後に残りの10パターンを入力したときの出力を観察した。すると,強化学習を行なっていないニューラルネットを用いた場合は,(a)のように,照明条件,背景のよって出力が変化し,強化学習を行なった後のニューラルネットを用いた場合は,(b)のように,AIBOがいるかいないかで出力が変化していることが分かる。このことから,強化学習を通して,照明条件や背景によらずにAIBOが中央にいるかいないかの表現を獲得したと言える。

動画 歩行タスクの学習後のテストの動画(ダウンロード,WMVファイル(10MB),MPGファイル(21.98MB)
参考文献
K. Shibata \& T. Kawano: Acquisition of Flexible Image Recognition by Coupling of Reinforcement Learning and a Neural Network, JCMSI, submitted
K. Shibata \& T. Kawano: Learning of Action Generation from Raw Camera Images in a Real-World-like Environment by Simple Coupling of Reinforcement Learning and a Neral Network, Proc. of ICONIP, submitted
4.3 異種センサ信号の抽象化と知識転移の学習
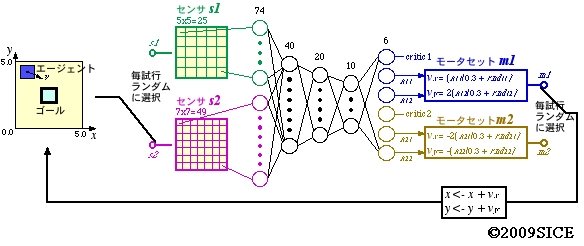
図4-3-1 異種センサ,異種モータの中から毎試行ごとに一つずつランダムに選択されて同一のタスクを学習するシステムの構成。タスクは,エージェントが2次元平面上を動いて,ゴール二到達すれば報酬が得られる設定となっている。
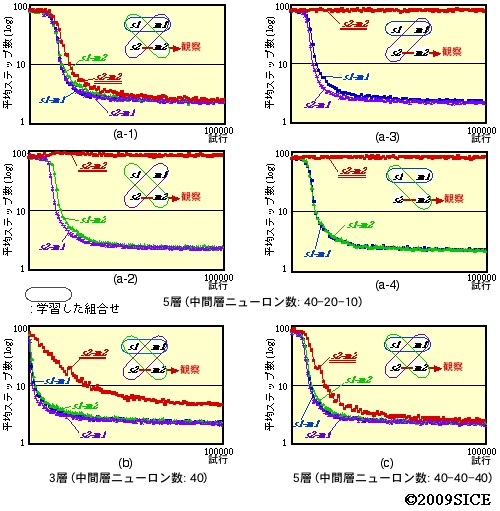
図4-3-2 学習後のセンサーモータの各組み合わせに対するゴールまでの平均ステップ数の変化。長い丸で囲まれたものが,学習時に現れるセンサーモータの組み合わせを示す。s2-m2の組み合わせは学習時には現れない。(a-1,..,4)は,学習時に現れるセンサーモータの組み合わせが異なる。(a)はニューラルネットが5層で,中間層ニューロン数が下から40-20-10個の場合。(b)は3層で中間層ニューロン数が40個,(c)は5層で,中間層ニューロン数がすべて40個の場合。s2-m2以外の組み合わせを学習すると,s2-m2の場合もゴールにたどり着けるようになっていることが分かる。しかし,3つのうち1つの組み合わせでも学習されないと,s2-m2の組み合わせはうまくゴールに行けないことが分かる。また,ニューラルネットの構成によっても,パフォーマンスが大きく異なることもわかる。
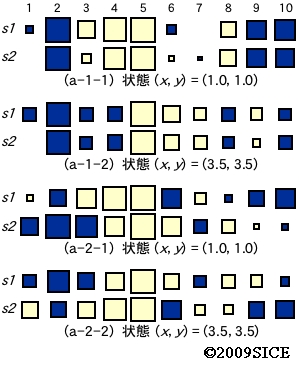
図4-3-3 図4-3-2の(a-1)の場合と(a-2)の場合での,2つの状態に対するs1を使った場合とs2を使った場合での一番上の中間層ニューロンの(出力)表現を比較したもの。色が出力の符号,大きさが絶対値を表す。ここでは,-0.5から0.5のシグモイド関数を出力関数として使用。(a-1)の場合には,2つの状態の場合のいずれも同じ状態であれば,中間層表現が非常に近いことがわかる。つまり,学習を通して,入力が全く違っても,似た内部表現が得られるようになっていることがわかる。
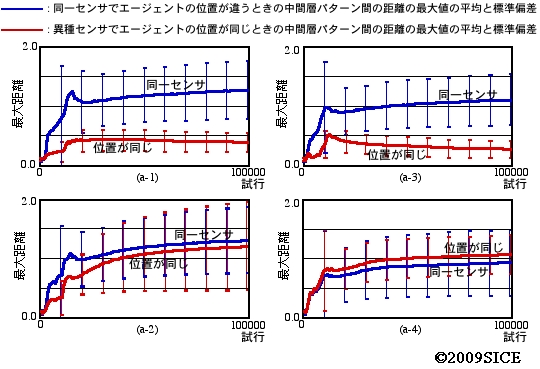
図4-3-4 図4-3-2での(a-1,..,4)のセンサーモータの4つの組み合わせの場合の,同一センサでエージェントの位置が異なる場合の中間層パターン間の距離の最大値の平均と標準偏差,異種センサでエージェントの位置が同じ場合の中間層パターン間の距離の最大値の平均と標準偏差をプロットしたもの。(a-1)(a-3)の場合には,異種センサでも物体の位置が同じであれば,中間層パターンが近いことが分かる。
参考文献
K. Shibata: Spatial Abstraction and Knowledge Transfer in Reinforcement Learning Using a Multi-Layer Neural Network, Proc. of Fifth Int'l Conf. on Development and Learning (2006)
4.4 コミュニケーションの学習と信号の2値化
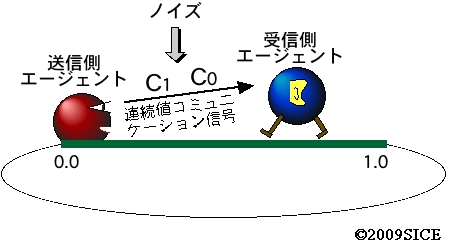
図4-4-1 コミュニケーション学習の際のタスク。送信側エージェントは,相手のエージェントの位置を観察でき,コミュニケーション信号を2回発することができるが,移動手段を持たない。一方,受信側エージェントは,相手の発した2回のコミュニケーション信号を聞くことができ,さらに,移動することができるが,相手のエージェントの情報を知ることができない。そして,受信側エージェントが送信側エージェントの近くまで移動すると報酬がもらえる。空間は1次元で,リング状となっているが,移動量が大きすぎても,通り越えてしまい,報酬は得られない。受信側エージェントは-0.5から0.5の連続値の移動距離を選択でき,適切に移動すれば,つまり,0.5より左の場合は左に,右の場合は右に適切な量だけ移動すれば,1回の移動でゴールすることができる。ここでは,2回のコミュニケーションの機会を有効に使って必要な情報を伝達することができるようになるか,そしてさらに,コミュニケーション信号は連続値であり,交信時にノイズを付加することで,強化学習によって,耐ノイズ性向上のために信号が二値化されることがポイントとなる。
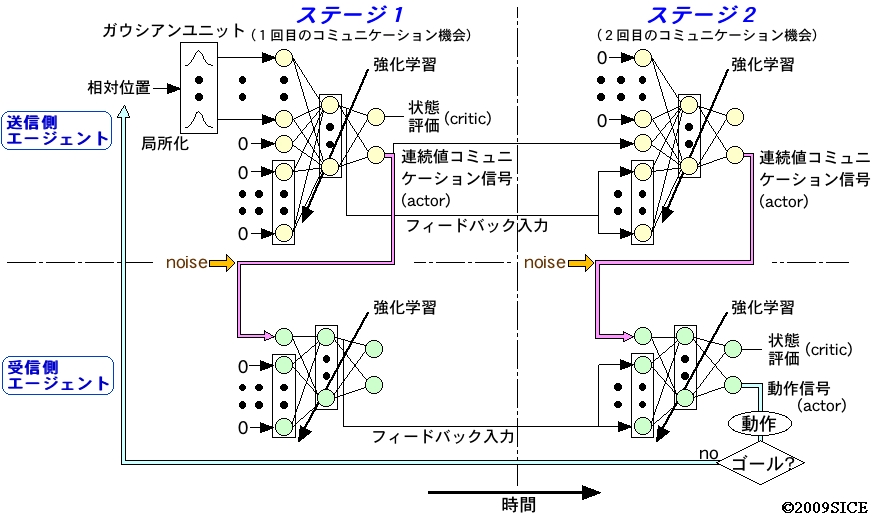
図4-4-2 システムの構成と信号の流れを示した図。両エージェントともリカレントニューラルネットを持ち,actor-criticeの構成であり,得られた報酬にしたがって学習する。送信側は,相対位置をガウシアンユニットを通してからリカレントニューラルネットに入力される。送信側エージェントは2回にわたってactorから信号を出し,受信側エージェントは,ノイズがのったその信号を入力とする。そして,2つめの信号を受け取った後に,actorから出される値にしたがって動作する。
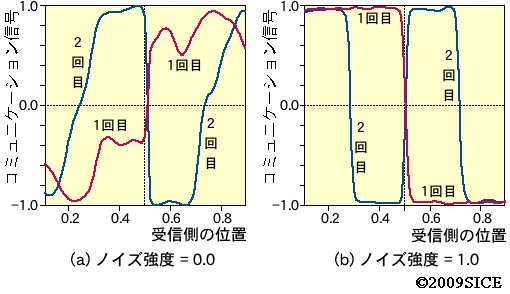
図4-4-3 学習後に,受信側エージェントの位置に対して送信側エージェントが発する信号をプロットしたもの。(a)はノイズを付加しなかった場合,(b)はノイズを付加した場合の信号を表す。いずれの場合も,1回目と2回目の信号が異なることがわかる。さらに,ノイズを付加した場合は,信号が-1.0か1.0の両極端になりやすいことがわかる。そして,1回目と2回目の信号で2bitの数のように4つの場合を表現できていることがわかる。

図4-4-4 学習後に,受信側エージェントの位置に対して,送信側のエージェントの信号に基づいて受信側エージェントが出力した動作信号。ピンク色の部分の動作信号を出すと,受信側エージェントはその動作後に送信側エージェントに近づいて報酬を得ることができる。ここからも,ノイズを載せた場合は,2値化された信号によって4つの離散的な動作信号のどれかを出力していることがわかる。
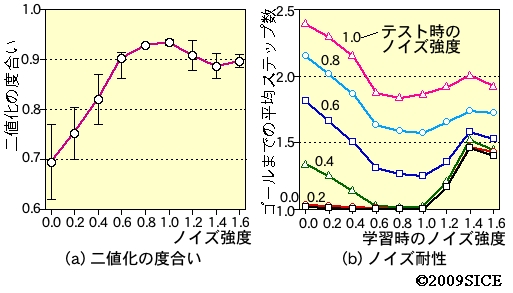
図4-4-5 ノイズの強度を変化させたときの信号の(a)2値化の度合いおよび(b)ノイズ耐性。ノイズが強くなるほど2値化の度合いが大きくなっていることがわかる。また,学習時にノイズ強度がある程度強いところで学習した方が,テスト時にノイズが入った時のゴールまでの平均ステップ数が小さくなることが分かる。